


A deep learning AI model developed by NVIDIA Research has been seen turning rough doodles into photorealistic images with astonishing ease. The tool leverages generative adversarial networks, or GANs, to convert segmentation maps into lifelike images.
The interactive app using the model, in a lighthearted nod to the post-Impressionist painter, has been christened GauGAN.

Post-Impressionist Paul Gauguin
GauGAN could offer a powerful tool for creating virtual worlds to everyone from architects and urban planners to landscape designers and game developers. With an AI that understands how the real world looks, these professionals could better prototype ideas and make rapid changes to a synthetic scene.
“It’s much easier to brainstorm designs with simple sketches, and this technology is able to convert sketches into highly realistic images,” said Bryan Catanzaro, vice president of applied deep learning research at NVIDIA.
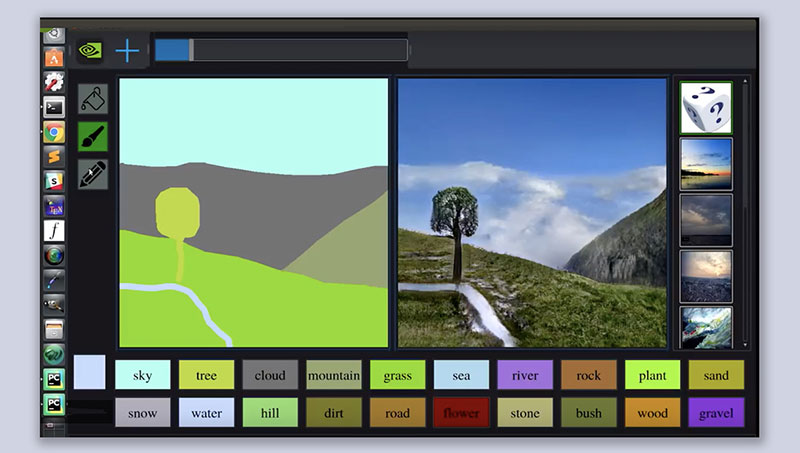
Catanzaro likens the technology behind GauGAN to a “smart paintbrush” that can fill in the details inside rough segmentation maps, the high-level outlines that show the location of objects in a scene.
GauGAN allows users to draw their own segmentation maps and manipulate the scene, labeling each segment with labels like sand, sky, sea or snow.

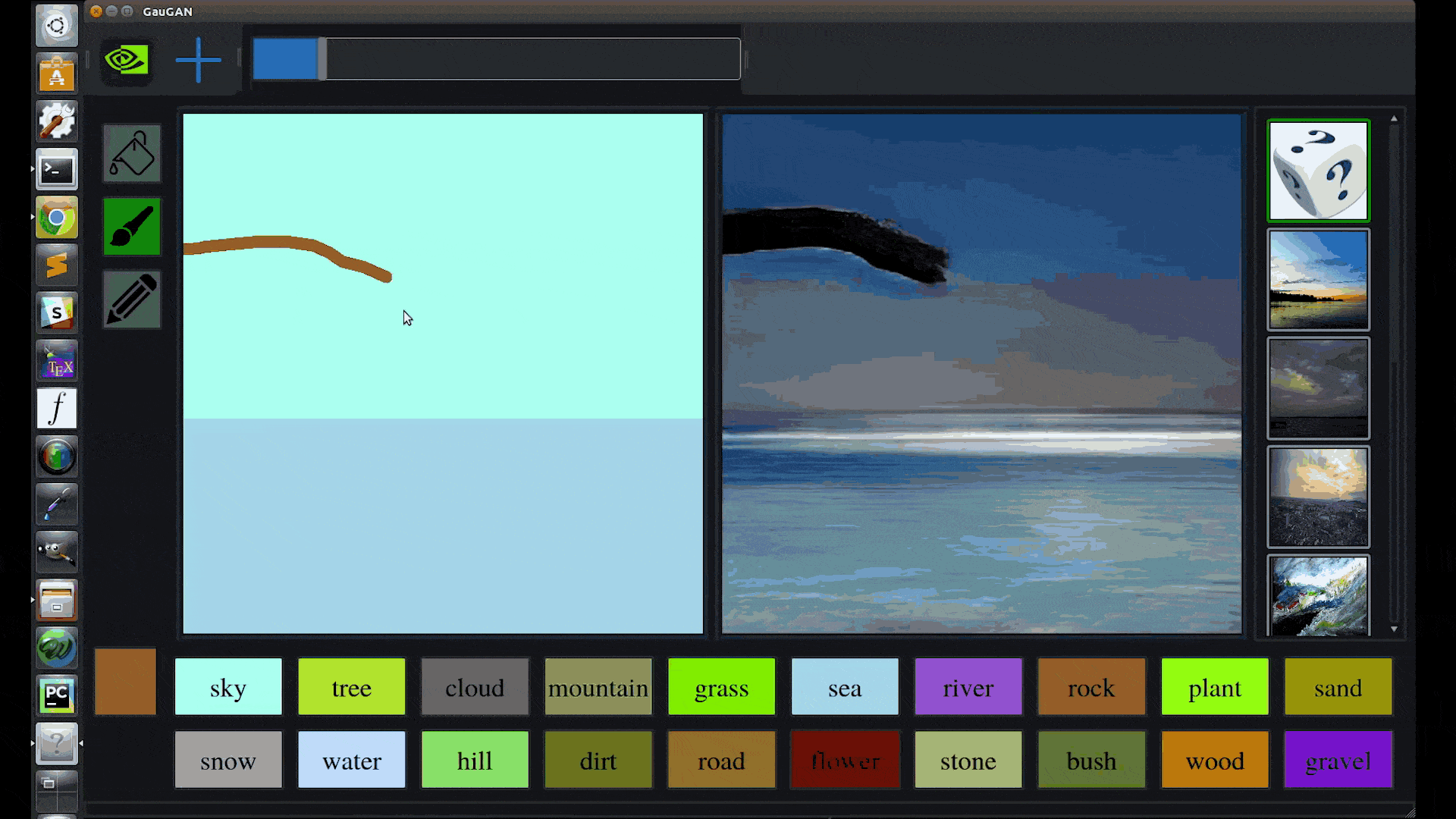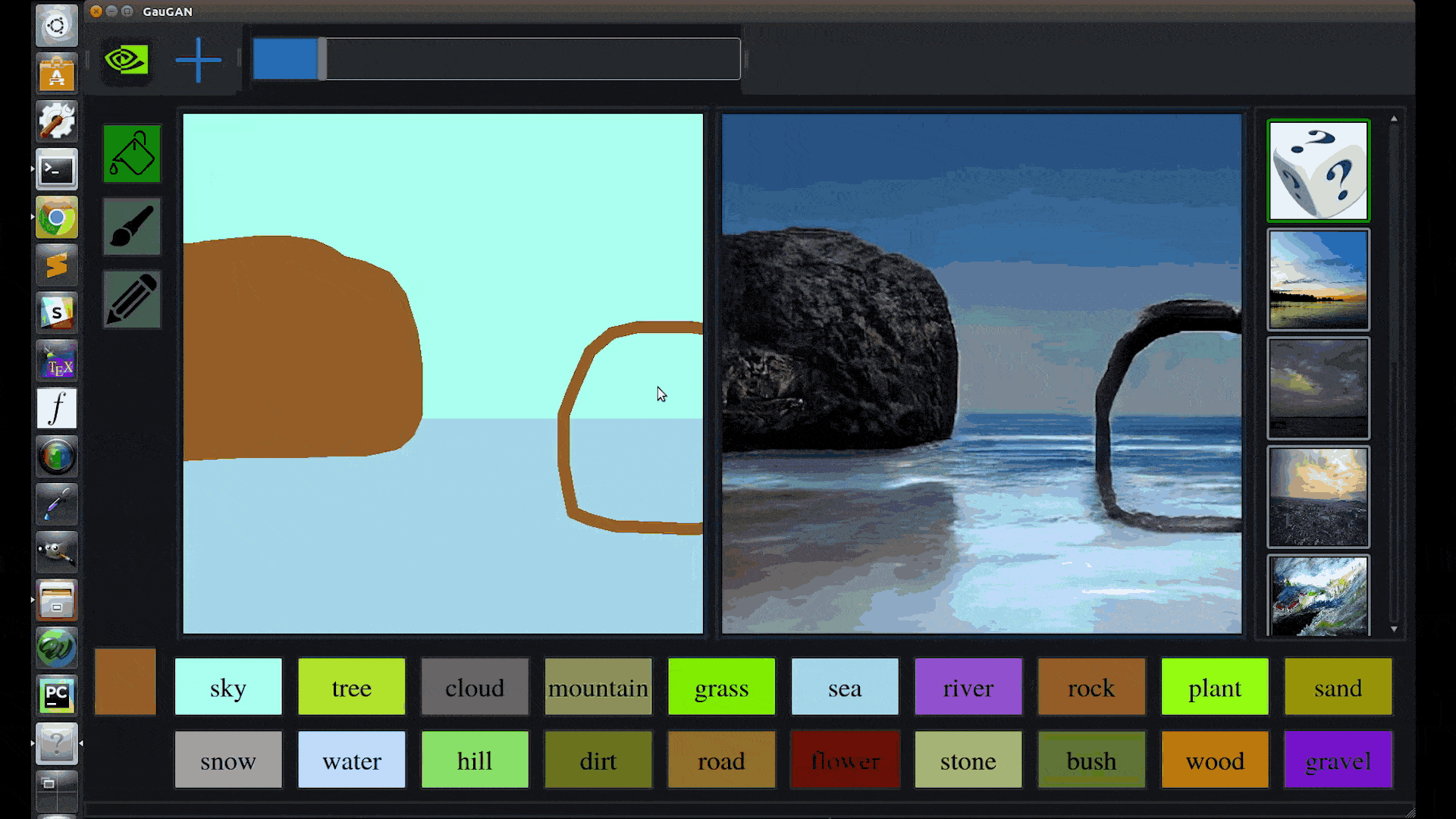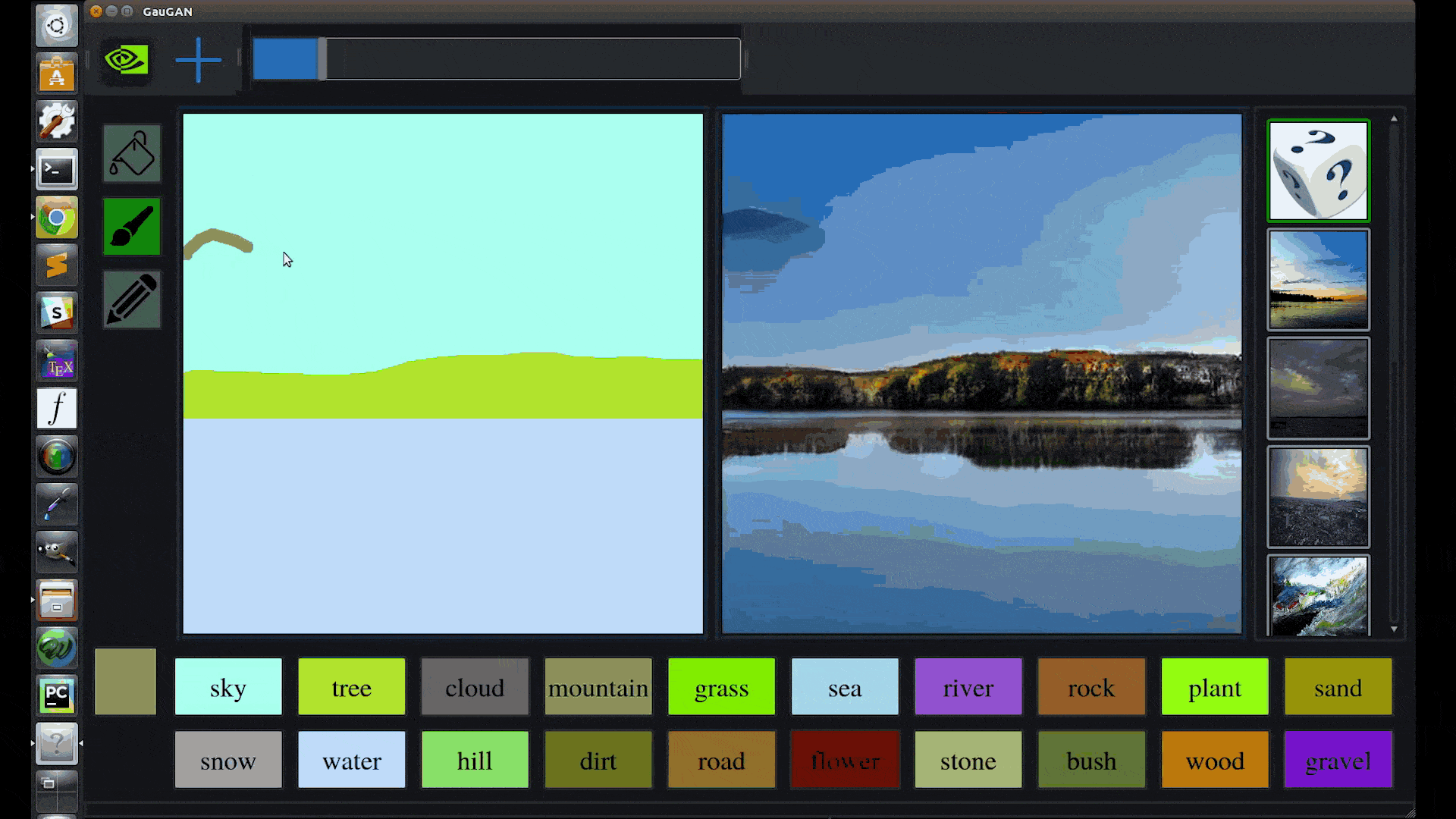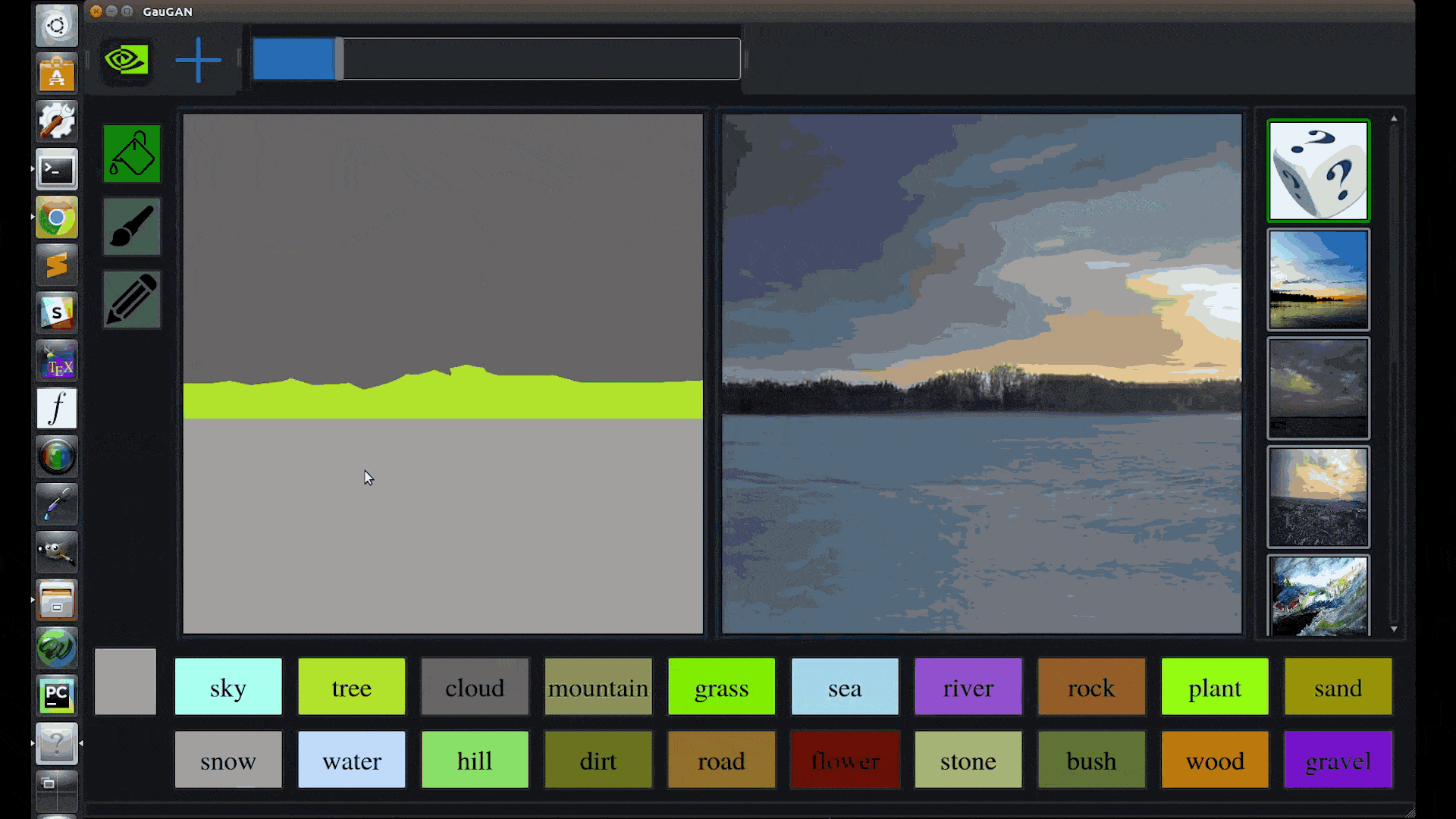
Trained on a million images, the deep learning model then fills in the landscape with impressive results: Draw in a pond, and nearby elements like trees and rocks will appear as reflections in the water. Swap a segment label from “grass” to “snow” and the entire image changes to a winter scene, with a formerly leafy tree turning barren.
“It’s like a coloring book picture that describes where a tree is, where the sun is, where the sky is,” Catanzaro said. “And then the neural network is able to fill in all of the detail and texture, and the reflections, shadows and colors, based on what it has learned about real images.”

Despite lacking an understanding of the physical world, GANs can produce convincing results because of their structure as a cooperating pair of networks: a generator and a discriminator. The generator creates images that it presents to the discriminator. Trained on real images, the discriminator coaches the generator with pixel-by-pixel feedback on how to improve the realism of its synthetic images.
After training on real images, the discriminator knows that real ponds and lakes contain reflections — so the generator learns to create a convincing imitation.

The tool also allows users to add a style filter, changing a generated image to adapt the style of a particular painter, or change a daytime scene to sunset.
“This technology is not just stitching together pieces of other images, or cutting and pasting textures,” Catanzaro said. “It’s actually synthesizing new images, very similar to how an artist would draw something.”




